Quick tip: Quickly parse and filter data with regex find and replace
Dealing with data is sometimes a pain in the rear end. It typically comes full of unwanted extras that can be a pain to filter out by hand. One of the most common ways of dealing with this is to write some kind of script which is time consuming or use a tool to clean it up and/or transform for you.
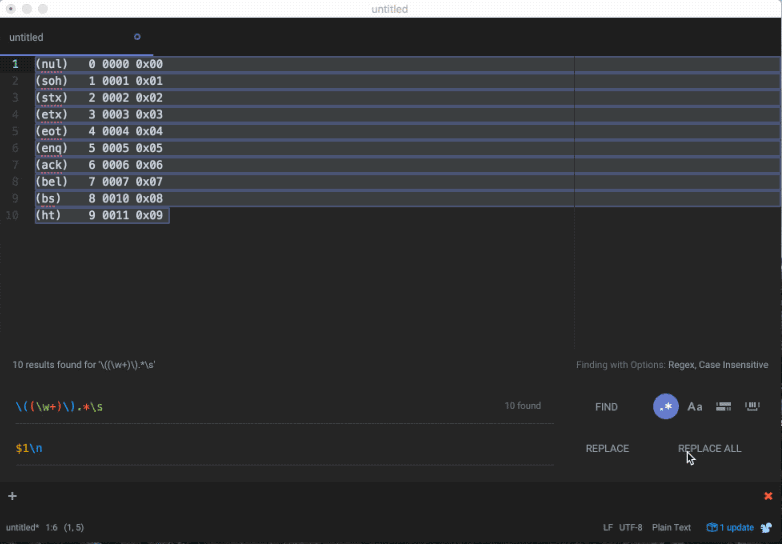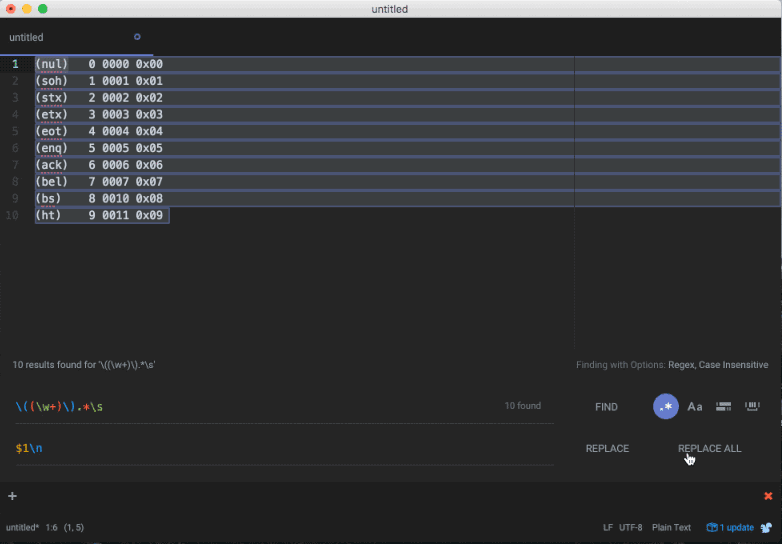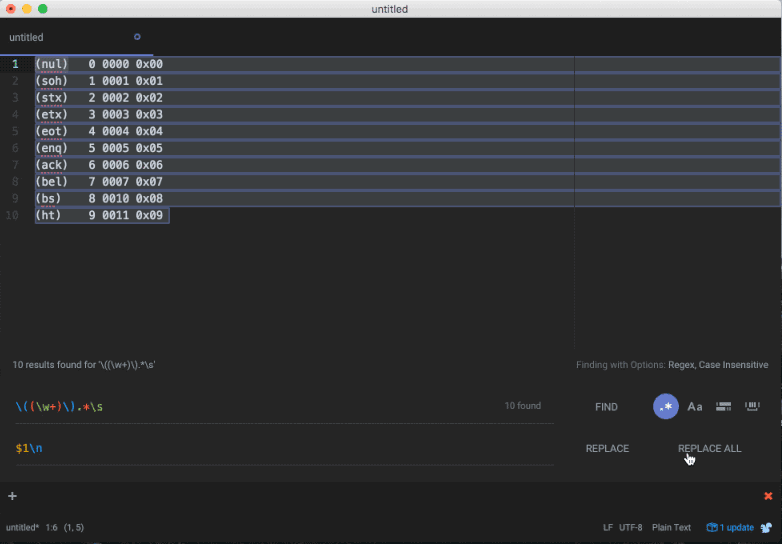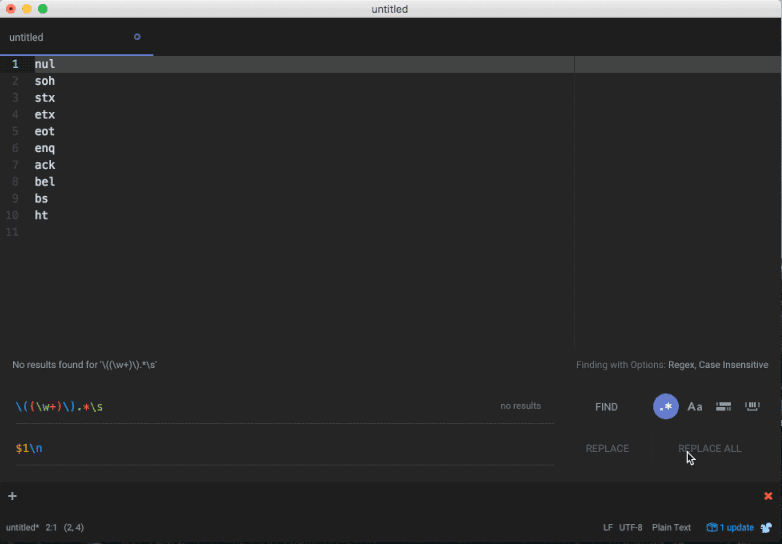
For example, given the data set[1],
(nul) 0 0000 0x00
(soh) 1 0001 0x01
(stx) 2 0002 0x02
(etx) 3 0003 0x03
(eot) 4 0004 0x04
(enq) 5 0005 0x05
(ack) 6 0006 0x06
(bel) 7 0007 0x07
(bs) 8 0010 0x08
(ht) 9 0011 0x09
In order to filter out the out the first column, I could use grep to return a list of anything contained in brackets using the command
grep -io \(.*\) file.txt
While this is perfectly fine, there are a few problems with it:
-
I have to create a file to search.
-
If my regex is off somehow, I don't get any feedback without examining the output.
Using regex find and replace
A quick way to do this would be to use the find and replace feature built into a lot of popular text editors today. For this demonstration I will be using atom.
cmd + f opens up the find and replace pane for the current buffer/file[1:1]. Selecting the .* puts it into regex search mode.
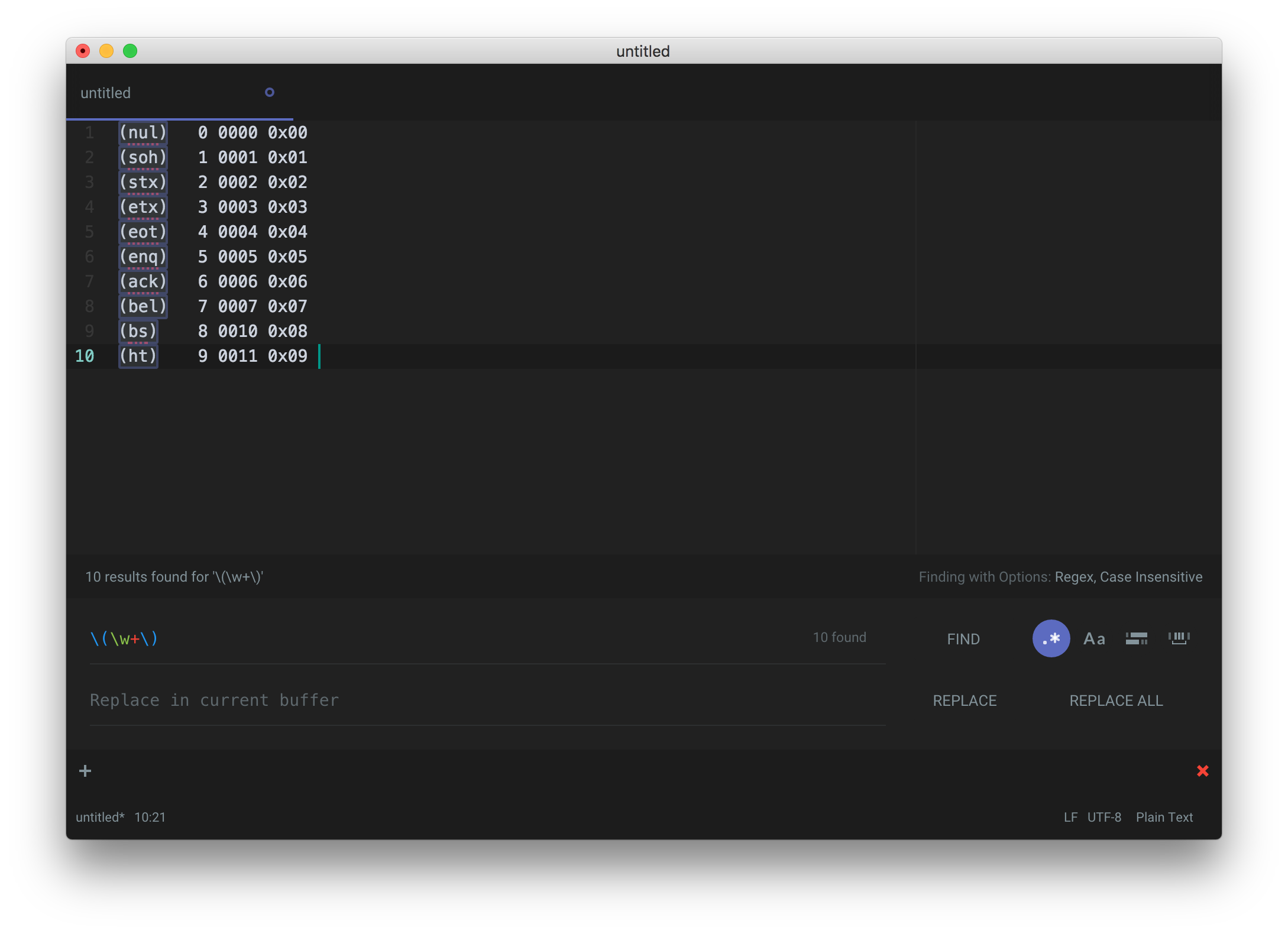
It easy to match the parts of interest using the expression \(\w+\). It's just as easy to match the entire line by capturing everything that follows until i encounter whitespace using \(\w+\).*\s.
Replacing the matched text works exactly as it sounds (content matched by the expression will be replaced by whatever text is provided). However since regex capture groups are supported, we can replace content while utilizing matched capture groups using the $ symbol for unnamed groups followed by the index.