Notes on - Why do LLMs freak out over the seahorse emoji?
A fantastic deep dive into the seahorse emoji phenomena[1] was recently published by Theia[2]. It's engaging, well presented and worth reading. The post presents a case using meta-llama/Llama-3.3-70B-Instruct. However I wanted to verify this behavior with smaller models which unsurprisingly fail the challenge as well.
I specifically tested microsoft/Phi-4-mini-Instruct and HuggingFaceTB/SmolLM2-135M-Instruct.
I started with the code sample Theia provided here and made some modifications that
- Added a CLI using typer to make it easier to iterate
- Print tables using
richfor nicer formatting - Save and compare activations
A few things stood out to me when testing.
Using microsoft/Phi-4-mini-Instruct, It's kind of interesting to see the early activations tend a bit more toward unsafe content before converging on the output[3].
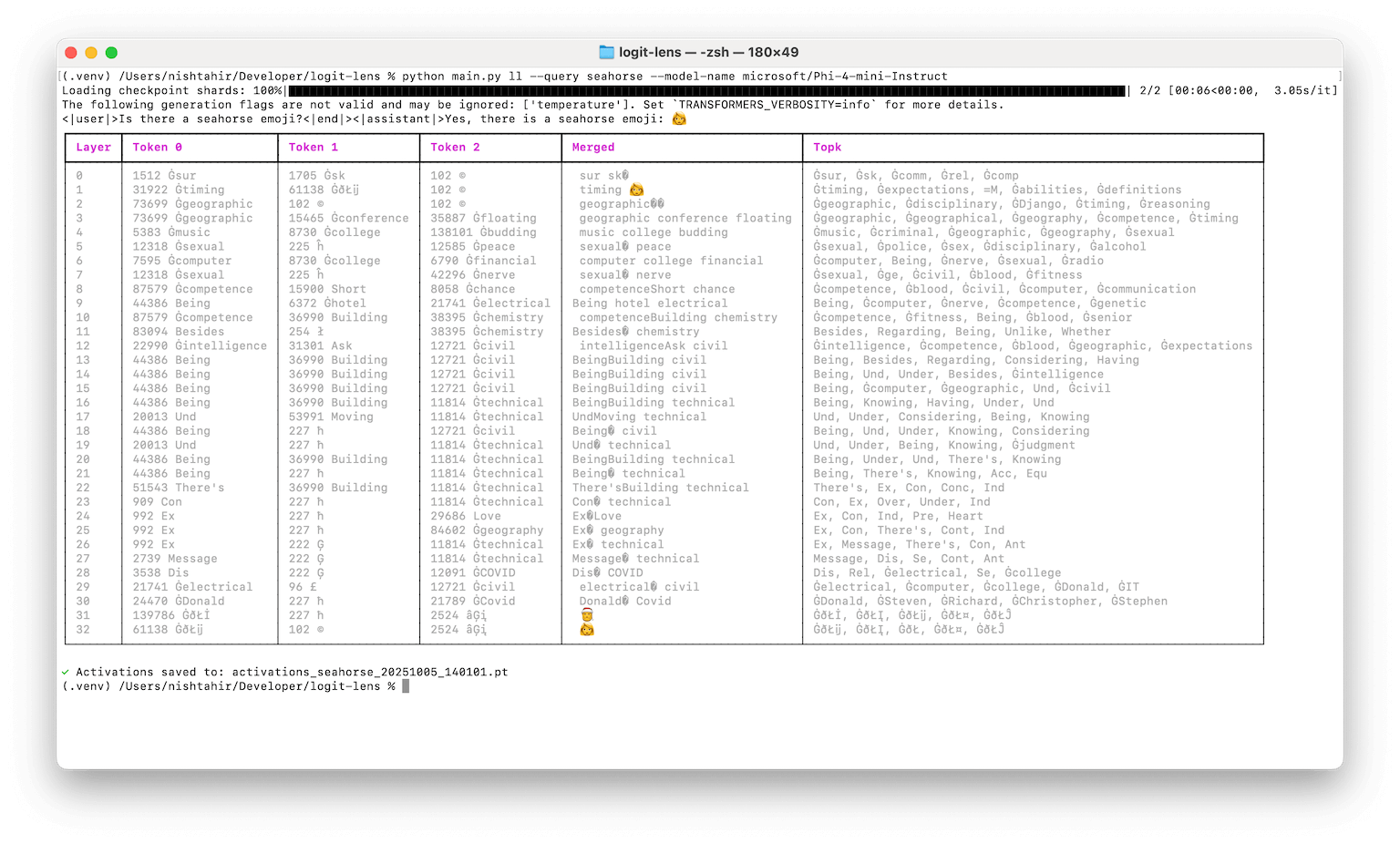
This is a bit more obvious when contrasted against SmolLM2 whose output looks a bit more arbitrary to me.
We can compare the layer activations of a few different queries generated using microsoft/Phi-4-mini-Instruct to see how they differ. My goal was to determine whether the queries are processed the same way.

Intutively we can see that at first the queries are processed similarly but diverges around layer 20 as the model begins to converge on an output.
Here's a plot generated with smollm2.
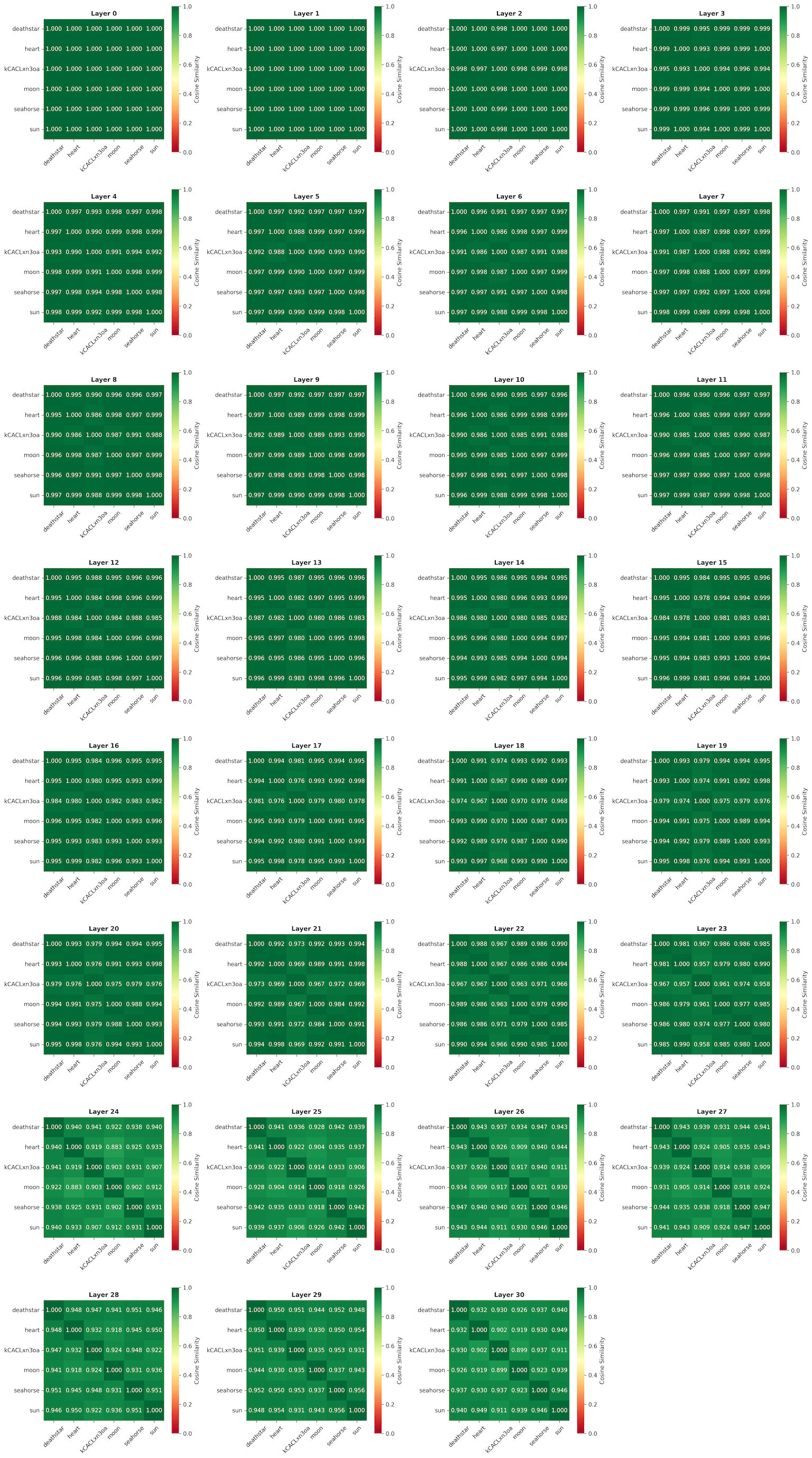
Similarly it all starts off the same and begins to diverge around layer 23.
I made a git repo that anyone can build off of here
(no date) www.reddit.com. Available at: https://www.reddit.com/r/GeminiAI/comments/1nglzed/gemini_loses_its_mind_after_failing_to_produce_a/ (Accessed: 2025-10-5). ↩︎
(no date) Why do LLMs freak out over the seahorse emoji?. vgel.me. Available at: http://vgel.me/posts/seahorse/ (Accessed: 2025-10-5). ↩︎
COVID being mentioned is not where I expected this experiment to go. It's fun surprises like this that keeps things interesting. ↩︎