Is GitHub Copilot For Everyone?
I've been using GitHub Copilot (Copilot) for almost a year. As discussed in a previous write-up, I consider it a modern iteration of IntelliSense or autocomplete. If you're not yet acquainted with it, Copilot serves as an IDE integration that leverages the context surrounding your code to generate a "fill in the blank" completion as an autocomplete suggestion. Trained on code from public GitHub repositories[1], Copilot is capable of generating code snippets in various languages. Operating under the hood of this tool is a Large Language Model, excelling at recognizing patterns that it uses to make relevant predictions about the user's intent. When provided with sufficient context in code, it often does a good job of anticipating my needs. However, it's far from perfect[2].
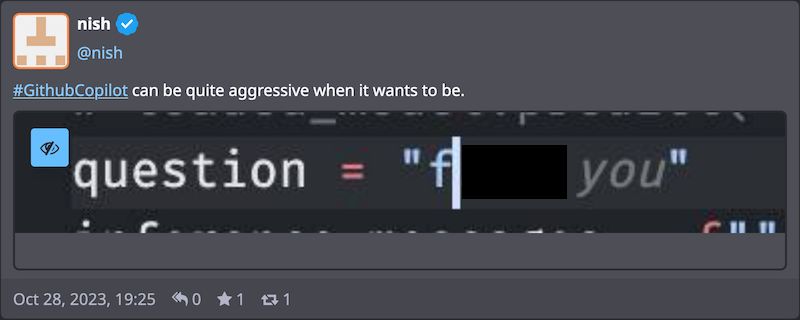
Essentially, Copilot amounts to GPT-4[3] embedded in your editor, complete with its advantages and drawbacks. As an auto-complete engine, it tends to favor solutions that are likely to be accepted in the current context. Those solutions are not always the optimal one. It is not a substitute for having a solid grasp of the target language or the problem at hand. While I've managed to integrate Copilot into my workflow, many developers I've spoken with have not shared in my experience. Their frustrations often stem from mismatched expectations around Copilot's capabilities (possibly fueled by AI hype), only to be disappointed when it falls short.
"Management asked us to use it because it was supposed to make us more "productive". However, I found that I spent most of the time fixing all the broken code that it suggested so I turned it off" - Disgruntled Engineer
Despite its straightforward setup, there's an underestimated learning curve to Copilot that accompanies its technology. Grasping its limitations and strengths becomes the differentiator between Copilot being an asset or a hindrance in your workflow.
Where Copilot can be helpful
Boilerplate
In my experience, Copilot shines brightest when faced with tasks involving extensive boilerplate. It's amazing at tasks such as generating mock JSON for test data, creating documentation from the function body, and generating tests based on the implementation. Providing Copilot with enough context through code or API docs is usually enough information for it to generate code relevant to the situation.
The takeaway from our qualitative investigation was that letting GitHub Copilot shoulder the boring and repetitive work of development reduced cognitive load. This makes room for developers to enjoy the more meaningful work that requires complex, critical thinking and problem solving, leading to greater happiness and satisfaction.[4]
The added mental bandwidth to concentrate on the core problem rather than wrestling with boilerplate code is huge and is often cited as the major driver in developer satisfaction[4:1]. Removing the boring and repetitive aspects of coding allows developers to focus on the problems that actually matter to them.
What you need is obvious
If you have a clear idea of what you want to do, the challenge becomes writing out the outline for Copilot to fill in. The more obvious the context is, the more likely it is to generate the code you want.
I found programming to be relatively easy with Copilot's assistance. At first, I was not entirely confident in its suggestions, as some parts of the code it proposed were not completely accurate. However, as our codebase grew, Copilot's predictions became increasingly precise. One area where I particularly appreciated Copilot's help was during code cleanup and refactoring. Its auto-completion tools were highly effective in these tasks, making the process much smoother. - Ana Robles[5]
Interestingly, because it keys off of the code in the codebase, your code now serves an additional purpose. It is now a giant prompt for AI Code completion. A codebase that is well structured for this task will improve the quality of suggestions over time. I call a codebase that is engineered to do this well "Copilot-friendly code".
Copilot-friendly code, when taken to the extreme, is a codebase that is engineered to be as predictable as possible. This means that the AI assistants are more likely to generate predictable and correct suggestions.
Source to Source Translation
Anecdotally, I've found GPT-4 to be great at translation tasks. It's been quite accurate in translating idioms in code from one language to another while taking into account subtler differences in their respective APIs. It doesn't always pick the optimal solution but it's been a net time saver in my experience.
Some companies have found decent success in using GPT-4 to assist in porting code written in unsafe languages to safer ones.
We decided to focus on tasks that used the LLM to refactor code where the behavior of the program should not change. Many of these tasks exist in the translation of C to Rust and the incremental rewriting of unsafe, unidiomatic Rust to safe, idiomatic Rust.
...
GPT-4 was able to successfully create all 20 Rust macros that compiled to HIR equivalent to the original function. Producing Rust code that targets C2Rust HIR output requires creating an unusual, unidiomatic form of Rust. In 20 minutes of googling I was unable to find any examples of anyone doing something similar to this, with or without an LLM. This indicates the task is probably not present in its training data, yet GPT-4 was successful. This corresponds with other tests I’ve done using GPT-4, such as having it perform arithmetic in non-standard formats such as base 9.[6]
Where Copilot can be dangerous
Copilot will give you exactly what you asked for not what you need
When exploring new tools or APIs, a lot of research usually takes place before writing a single line of code. This includes looking into concerns such as approach, security considerations, and best practices.
Copilot does not do this. Copilot is not thinking critically about your code, nor is it assessing the overall quality of the solution you are developing, it is only biased to generate what is most likely to be accepted. The generated code may be idiomatic and fit into the given context well but may not pass the sniff test when viewed critically. Thinking critically is the Developer's job. If they are relying on Copilot to teach them what is correct, you have a situation of the blind leading the blind.
My method for addressing this is to use Copilot strictly as an auto-complete engine. This means that I generally have a good idea of exactly what I want before writing a line of code. This means I'm only ever accepting generated code that matches my intent and never the other way around.
It's only as good as its training data
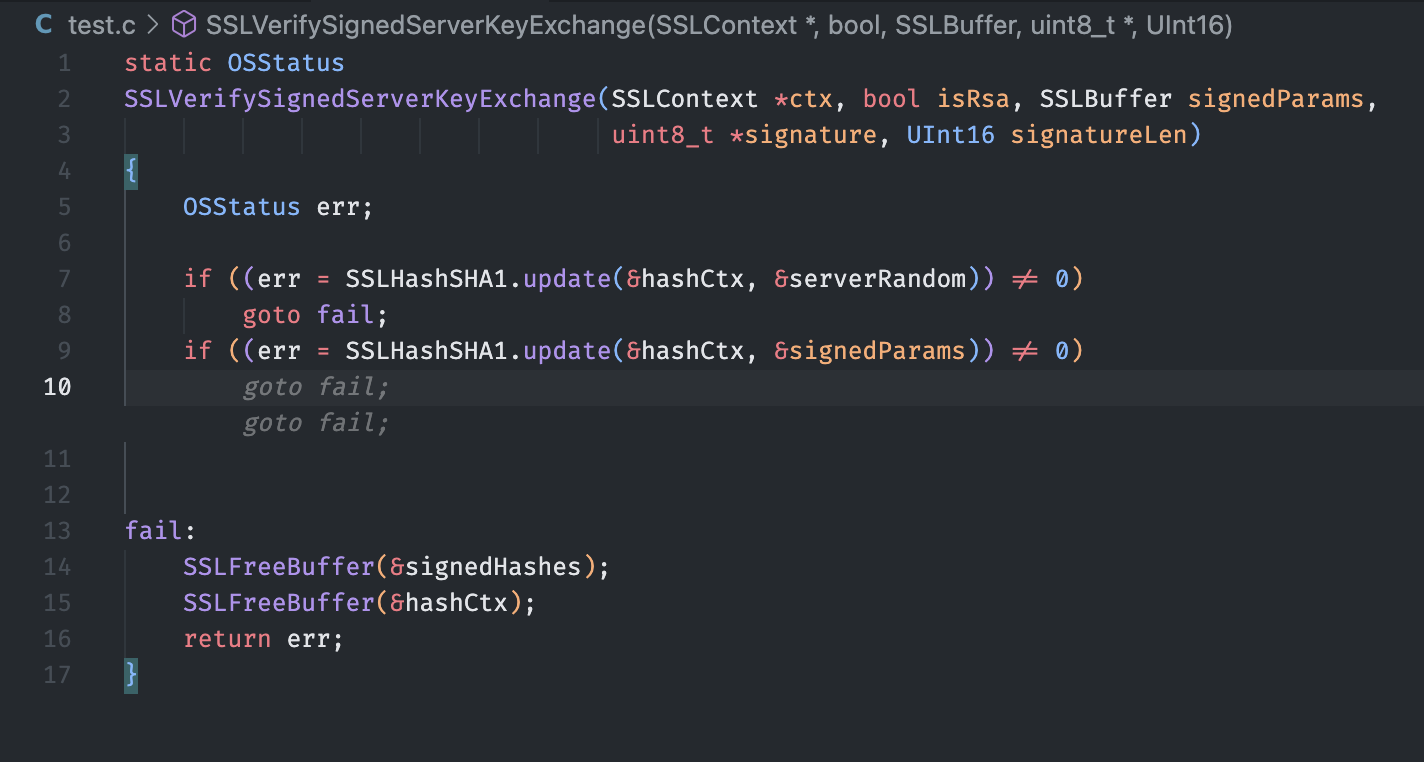
Because Copilot is trained on public code[1:1], it's seen a lot of code and not all of that code is well-written or safe[7]. Without additional context in the codebase, I've found that it's likely to reproduce common mistakes and bugs if they are common enough in the wild. I've found that it will not properly sanitize user input or handle nonhappy path scenarios without additional prompting. It will also reproduce heavily cited security vulnerabilities like the infamous goto fail bug[8] if your code is similar enough.
Overall, Copilot’s response to our scenarios is mixed from a security standpoint, given the large number of generated vulnerabilities (across all axes and languages, 39.33% of the top and 40.73% of the total options were vulnerable)[9]
Granted this research was published a while ago and it's possible that the training data has been improved since then. However, it does provide some context on the fact that one should not trust Copilot blindly. This is not to say that Copilot is inherently insecure. It's just that it's not inherently secure either. As a developer, you ultimately own the code that you ship and it's your responsibility to audit and make sure the code you are shipping is secure.
Not all Generated code is equal
Because Copilot offsets the burden of writing code, developers are more likely to write code that is not well thought out. The main measure of success cited by proponents of Copilot is the speed at which they can write code
...developers who used GitHub Copilot completed the task significantly faster–55% faster than the developers who didn’t use GitHub Copilot.[4:2]
While this is an important metric, it's not a good This is not a good measure of code quality. It does not consider the shelf life, maintainability, or security of the code. Because Copilot suggests are additive in nature, it's incapable of suggesting refactors or changes to existing code. This means that it's possible to end up with a lot of code that should not have been written in the first place[10].
In my opinion, this is actually reflected in GitHub's own research[11].
we grouped developers into quintiles based on their experience, as measured by their average number of repository actions on the GitHub platform prior to their use of GitHub Copilot.
...
we found that acceptance rate is higher in this group. For example, the acceptance rate for the bottom quintile is 31.9%, whereas the acceptance rate for the top quintile is 26.2%. Developers in the bottom half of repository activity have a greater acceptance rate for GitHub Copilot suggestions than those in the top half This result is consistent with earlier research on skill benefits from generative AI[12].
This claims that the more experienced a developer is with a codebase, the less likely they are to accept Copilot's suggestions. While this is framed as developers with less experience benefit relatively more than more experienced developers, my interpretation of this is that the acceptance rate is lower because more experienced developers are more likely to recognize when the suggestions are not optimal for the given situation.
Copilot saves some time but not all the time
we found in a quantitative research study that developers completed tasks 55% faster with GitHub Copilot. Moreover, our early research found that 46% of code was completed by GitHub Copilot in those files where it was enabled.[4:3]
In my experience this is usually what is cited when discussing Copilot as a main driver of efficiency, however, it's not the whole story. There is additional time committed towards a project in areas not writing code that Copilot cannot assist with. This includes time spent reviewing and refactoring suboptimal code during maintenance.
We find disconcerting trends for maintainability. Code churn -- the percentage of lines that are reverted or updated less than two weeks after being authored -- is projected to double in 2024 compared to its 2021, pre-AI baseline. We further find that the percentage of 'added code' and 'copy/pasted code' is increasing in proportion to 'updated,' 'deleted,' and 'moved 'code. In this regard, AI-generated code resembles an itinerant contributor, prone to violate the DRY-ness [don't repeat yourself] of the repos visited.[13]
This means in an environment where Copilot is used incorrectly but introduced as an accelerator, the time saved in writing code may be offset by the time spent maintaining code that should not have been written in the first place. Copilot can be effective under certain situations but not under every circumstance and should not be introduced as a blanket 55% productivity booster.
Conclusion
Should everyone use GitHub Copilot (or any other AI-assisted code completion tool)? It depends - The benefits are real but there are very real pitfalls. It's better at some type of work than others and know it is at its most useful is the most important factor. That being said, It's still a very new tool and we're still collectively figuring out how to use it effectively. However, understanding the risks will help you make a more informed decision about the most appropriate time to use it.
So who should use Copilot? I think the people who stand to benefit the most right now are Senior developers who have enough judgment and experience to know when it's useful and when it isn't. While more junior developers can also benefit from it I think the true productivity gains are less pronounced while the risks of misuse are higher. They may be able to write more code faster but this means more code that needs to be reviewed and potentially rewritten. There are educational opportunities that Copilot introduces. For example, I've spent a decent amount of pairing time with junior developers on my team critiquing Copilot's suggestions. This has been a great way to teach them about best practices and common pitfalls in the language.
About github copilot individual (no date) GitHub Docs. Available at: https://docs.github.com/en/copilot/overview-of-github-copilot/about-github-copilot-individual (Accessed: 04 February 2024). ↩︎ ↩︎
Tahir, N (2024) social.nishtahir.com. Available at: https://social.nishtahir.com/@nish/statuses/01HDVVYERJ1H4JVTA8DYAFGCQV (Accessed: February 4, 2024). ↩︎
GitHub Copilot – November 30th update (2023) The GitHub Blog. Available at: https://github.blog/changelog/2023-11-30-github-copilot-november-30th-update/ (Accessed: February 4, 2024). ↩︎
Kalliamvakou, E. (2022) Research: quantifying GitHub Copilot’s impact on developer productivity and happiness, The GitHub Blog. Available at: https://github.blog/2022-09-07-research-quantifying-github-copilots-impact-on-developer-productivity-and-happiness/ (Accessed: February 4, 2024). ↩︎ ↩︎ ↩︎ ↩︎
Robles, A. (2023) “What we learned from using GitHub Copilot to develop a machine learning project,” Encora, 23 May. Available at: https://www.encora.com/insights/what-we-learned-from-using-github-copilot-to-develop-a-machine-learning-project (Accessed: February 4, 2024). ↩︎
Karvonen, A. (2023) Using GPT-4 to assist in C to rust translation, Galois, Inc. Available at: https://galois.com/blog/2023/09/using-gpt-4-to-assist-in-c-to-rust-translation/ (Accessed: February 4, 2024). ↩︎
I couldn't really find any concrete descriptions of how Copilot's training data is assessed for quality. I imagine there has to be some sort of process but it's not been made public to my knowledge so I can make an inference of the quality of the training data based off of the suggestions I've seen. ↩︎
“Understanding the Apple ‘GOTO FAIL;’ vulnerability” (2014) Synopsys.com, 25 February. Available at: https://www.synopsys.com/blogs/software-security/understanding-apple-goto-fail-vulnerability-2.html (Accessed: February 4, 2024). ↩︎
Pearce, H. et al. (2021) “Asleep at the keyboard? Assessing the security of GitHub Copilot’s code contributions,” arXiv [cs.CR]. Available at: http://arxiv.org/abs/2108.09293 (Accessed: February 4, 2024). ↩︎
Tornhill, A. (2023) The main challenge with AI assisted programming is that it becomes so easy to generate a lot of code which shouldn’t have been written in the first place, Twitter. Available at: https://twitter.com/AdamTornhill/status/1729592297887502611 (Accessed: February 4, 2024). ↩︎
Dohmke, T. (2023) The economic impact of the AI-powered developer lifecycle and lessons from GitHub Copilot, The GitHub Blog. Available at: https://github.blog/2023-06-27-the-economic-impact-of-the-ai-powered-developer-lifecycle-and-lessons-from-github-copilot/ (Accessed: February 4, 2024). ↩︎
Dohmke, T., Iansiti, M. and Richards, G. (2023) “Sea change in software development: Economic and productivity analysis of the AI-powered developer lifecycle,” arXiv [econ.GN]. Available at: http://arxiv.org/abs/2306.15033 (Accessed: February 4, 2024). ↩︎
Coding on copilot: 2023 data suggests downward pressure on code quality (no date) Gitclear.com. Available at: https://www.gitclear.com/coding_on_copilot_data_shows_ais_downward_pressure_on_code_quality (Accessed: February 4, 2024). ↩︎